- Stable Diffusion WebUI Basic 01–Introduction
- Stable Diffusion WebUI Basic 02–Model Training Related Principles
- Stable Diffusion WebUI Basic 03– FineTuning Large Models
Foreword of Stable Diffusion WebUI Basic
- Why is fine-tuning necessary in Stable Diffusion WebUI?
- Challenges in fine-tuning large models.
- Overview of common fine-tuning techniques (Dreambooth, LoRA, Embedding, Hypernetwork).
Why fine-tune large models?
Introduction to the UNET Model in Stable Diffusion WebUI
The UNET model we introduced earlier is the core network of Stable Diffusion (SD), containing billions of parameters. Training such a massive model requires significant resources—1.5 billion image-text pairs, 256 A100 GPUs running for 150,000 GPU hours, and an estimated cost of approximately 600,000 USD.
The Challenge for Designers
The problem with models designers are working with is that they are very complicated, and unlike programmers, it is very difficult to change them. This becomes increasingly difficult as designers do not possess the relevant technical expertise that makes it easy to alter parameters.
How Do We Improve It?
This is a core problem that stems from UNET oversimplifying the given frame and consequently making it difficult to achieve stylized results. Because of this problem, we look to incorporate performance improvements through modification of the UNET to better suit the task at hand.
How to Fine Tune Models Within Stable Diffusion
The next sections will cover some of the more important and widely used techniques employed in training models on Stable Diffusion. Today, I am not going to describe how exactly to train the model, but I will explain the theoretical background behind these techniques. Understanding these principles will undoubtedly make it simpler to tackle training techniques on your own.
These are very effective for modifying the model to meet the desired specification of the rendered image, and learning these will increase your productivity in working with Stable Diffusion.
Two Problems to Solve in Large Model Fine-Tuning
Introduction to Fine-Tuning Large Models In Stable Diffusion WebUI
Let’s monitor the two critical steps when custom tailoring big models within Stable Diffusion. Forget the plethora of technical intricacies and let us break down the picture that fine-tuning AI image synthesizers entails. The first step is ensuring whether you are using Stable Diffusion or any competing software. In using these services, there will always be two primary concerns.
- The Goldilocks Problem – It’s that sweet spot where one doesn’t get lost in the sea of overfitting or underfitting.
- The Efficiency Equation – Maximizing output quality while minimizing computational heavy lifting
Why Generalization Matters More Than You Think
Imagine teaching a child to recognize animals. If you only show them golden retrievers labeled “dog,” they might think all dogs are golden-colored and furry.
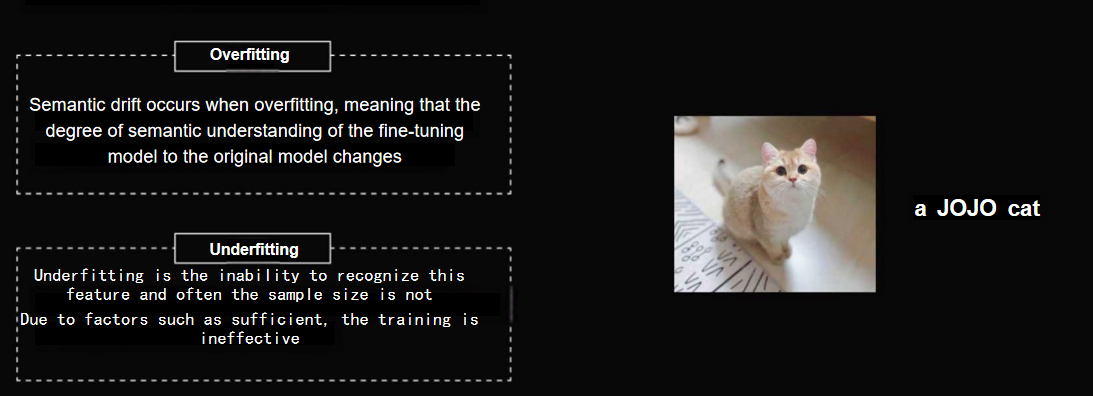
And now for AI speak:
Overfitting is when one becomes that overly enterprising student who so puts themself into a textbook that it sturdily blocking out any real world applications. For example, should I shove a hundred images of meow-meow “Jojo the tabby cat”, the model will forget that other types of felines exist. Ask me for just cat and I will make sure you get Jojo’s doppelganger every time. As a matter of fact, ask me once and you will get it every time.
Underfitting is, once again, the opposing problem. It’s like trying to learn French with a phrasebook that’s missing half the pages A literal cat in a hat doesn’t pronouns cat. The model makes no connections between the two.
Modern Solutions for Ancient Problems
The Stable Diffusion toolbox offers four key instruments to tune this balancing act:
- Dreambooth – The customization powerhouse
- LoRA – The efficiency expert
- Embeddings – The memory savers
- Hypernetworks – The adaptive learners
Let’s spotlight Dreambooth first – Google’s 2022 breakthrough that’s like giving your AI training wheels. Its secret sauce? The “context sandwich” technique. Want to teach it about Jojo without overwriting general cat knowledge? You’d feed it prompts like:
“Jojo cat [a tabby feline] enjoying catnip”
This dual approach maintains the model’s fundamental understanding while adding new capabilities – like teaching that overeager student to recognize specific breeds without forgetting what makes a dog a dog.
Dreambooth IN Stable Diffusion WebUI:
Dreambooth, introduced by Google in August 2022, is a fine-tuning technique that addresses overfitting issues effectively. The key to its success lies in pairing “feature words + category” together during training. For instance, if you want to train a model of a cat named JOJO, but want to avoid overfitting the word “cat,” you would input it like this: “JOJO cat is a cat named JOJO.”
This method ensures that the AI understands “JOJO cat” refers to a specific cat, Jojo, without confusing the word “cat” with the unique features of Jojo, thus preventing overfitting.

Dreambooth’s Purpose and Capabilities
Let’s monitor the two critical steps when custom tailoring big models within Stable Diffusion. Forget the plethora of technical intricacies and let us break down the picture that fine-tuning AI image synthesizers entails. The first step is ensuring whether you are using Stable Diffusion or any competing software. In using these services, there will always be two primary concerns.
When Dreambooth was first introduced, it impressed many at the Microsoft Developer Conference with its ability to restore intricate details. In one example, the model precisely captured a “yellow 3” next to an alarm clock, showing its power to retain and generate specific features.

As you can see in the original image, there is a “yellow 3” to the right of the alarm clock, and Dreambooth perfectly restored it. This shows that using Dreambooth can indeed capture the visual features of the model you want in full detail, which is why it was quite impressive when it was first released.
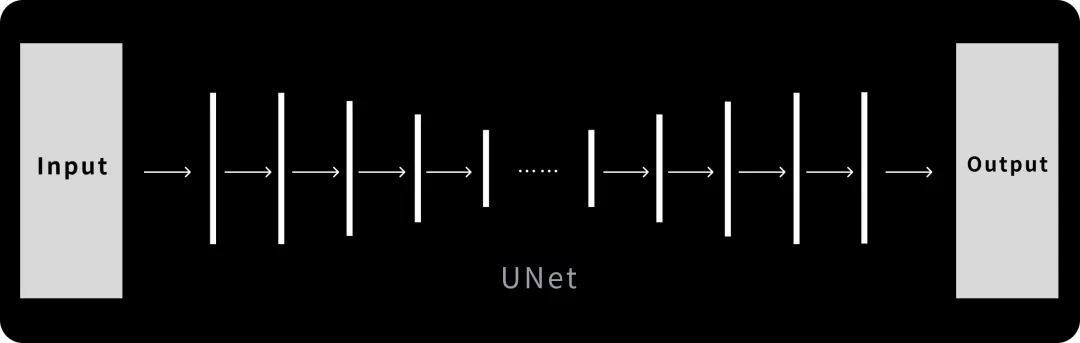
Dreambooth Fine-Tuning: Deep Integration with UNET
Dreambooth fine-tunes every internal parameter of the UNET algorithm, adjusting each layer for optimal output. This thorough adjustment results in significant model changes, shown in red parts of the image. As such, the benefits and drawbacks of Dreambooth are quite evident.
Advantages of Dreambooth
- Perfect Integration of Visual Features: Dreambooth excels at capturing and integrating fine visual details into the model, providing more accurate and detailed outputs.
Disadvantages of Dreambooth
- Time-Consuming Training: Since it adjusts every internal parameter of the UNET model, Dreambooth requires long training times.
- Large Model Sizes: Due to the extensive adjustments made, the fine-tuned models tend to become larger, making storage and management more challenging.
In summary, Dreambooth offers exceptional capabilities for fine-tuning models to capture intricate details, but it comes with the trade-offs of longer training times and larger model sizes.
LoRA IN Stable Diffusion WebUI :
After discussing Dreambooth, let’s move on to LoRA, a technique many of you may have heard about and are eager to learn more about. Let’s dive into its principles and how it differs from Dreambooth.
Understanding the UNET Algorithm and Fine-Tuning
To understand how LoRA works, we first need to revisit the UNET algorithm, the core network behind Stable Diffusion (SD). If you remember from earlier discussions, UNET is made up of many stacked computational layers. You can think of each layer as a small function, where the output of one layer becomes the input for the next. Through these layers, the model processes and understands the features of the data it receives.
In Dreambooth, we fine-tune every layer of the UNET model, which requires substantial computational resources, long training times, and results in large model sizes.
LoRA: Striving Towards Better Efficiency
On the other hand, LoRA adopts a differing stance. Its main objective while developing LoRA is to lower the overall training parameters and increase its efficiency. LoRA accomplishes this by freezing the pre-trained model’s weights and only injecting the training parameters into the layers of the transformer function architecture. This allows LoRA to change the model and tailor it to their needs while preserving the original models outline. Because of this, it can be easily implemented without effort, like a “plugin for play” system.
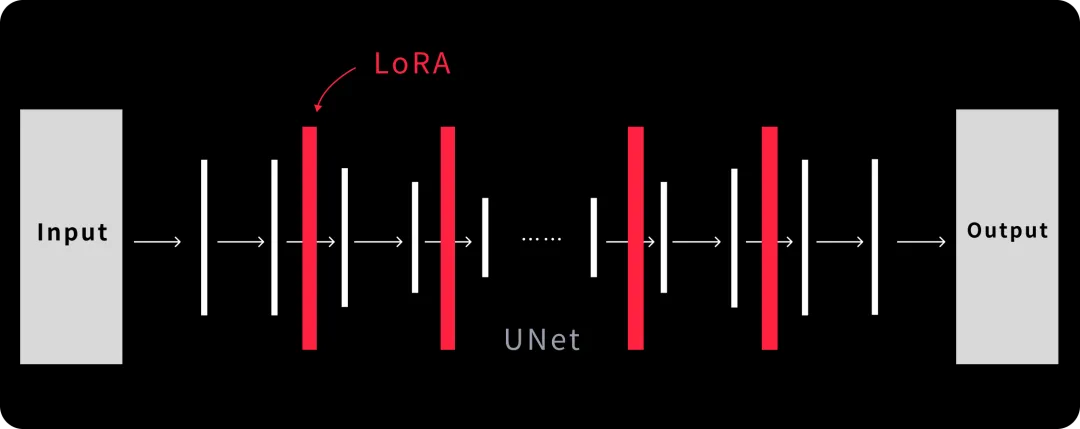
LoRA’s advantage is in using fewer layers of injection than Dreambooth, making the process as simple as possible. As such, LoRA is able to achieve a factor 1000 reduction in training parameters alongside a drop of three in CPU requirements. This makes LoRA highly useful and accessible due to the drastic decrease in model sizes.
The Practicality of LoRA Models in Stable Diffusion WebUI
If you are to download models from C站, for example, you would observe that the bulk of LoRA models do not exceed a few dozen megabytes while larger models can reach several gigabytes. Such additional features make LoRA perfect for users who have limited resources or require a rather easy approach for day to day tasks.
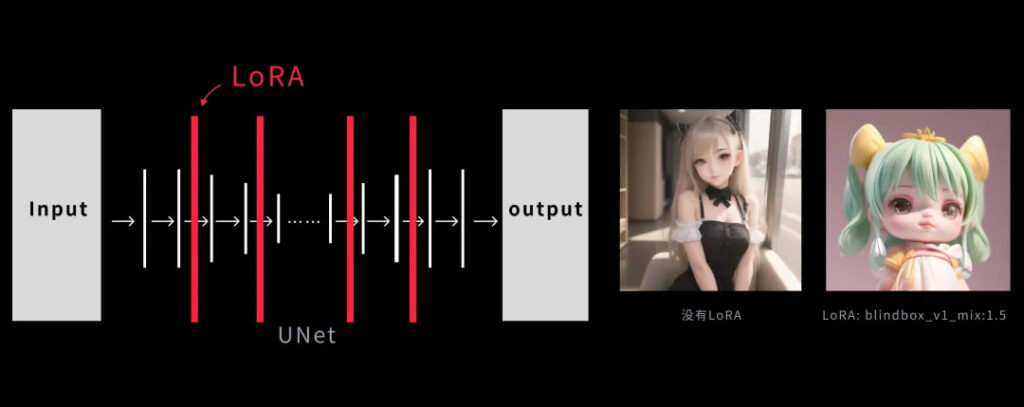
LoRA as a “Filter” for Style Customization
When dealing with AIs, LoRA can be considered a way of adding a filter over an existing model. The core information of the model remains unchanged so that the LoRA gets the model to the desired style. For example, while using the base model “revAnimated” which is biased towards anime, I am able to use LoRA to get a blind-box effect. With no changes to the prompt but using this filter, the expectation is a more blind-box model output as seen in the picture below.
Embedding IN Stable Diffusion WebUI :
Let’s now move on to embedding also known as text inversion which you might have seen while downloading models in C站. Embedding is a technique used for building a map between a certain prompt and the corresponding vector (numerical descriptor) that is trained to specific people, objects or concepts.
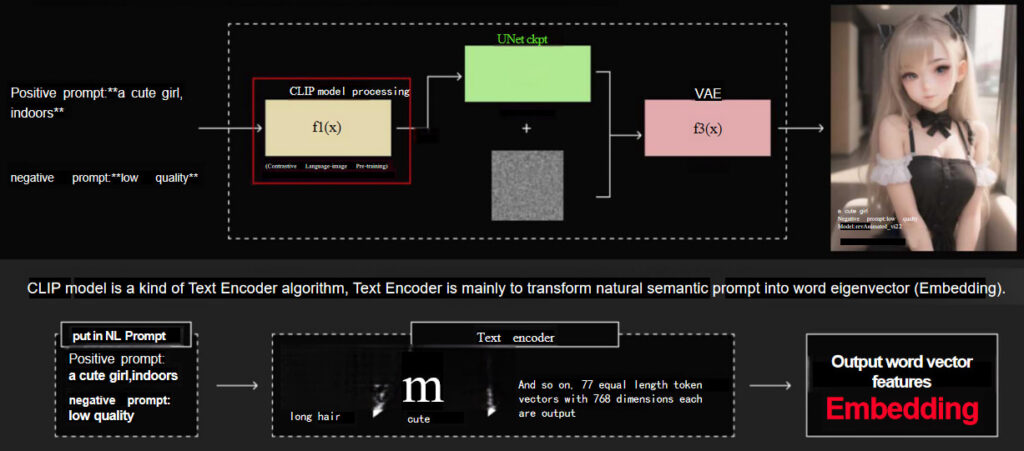
The function of CLIP and embedding
Let’s go back to the discussion on the CLIP model. As a Text Encoder, the primary task of CLIP is to translate a natural language prompt into a word vector or embedding. A model can be trained to relate prompts to certain mapped vectors and as a result, images can be generated for particular objects or people.
Since Embedding is narrow in scope and focuses on building a map between words and vectors, the resultant model size is ridiculously small, often measuring only a few hundred kilobytes.
Specific instance: A Character Model
Let’s examine a case using the popular character D.Va from Overwatch.
If D.Va’s image needed to be generated, it is likely that an extensive tag list like physical attributes, personality traits and numerous others would be essential to accurately depict her. Embedding would solve the problem of long lists of description.

Instead of a thousand tags, we can combine all those tags into a new word, OWDva, which does not exist in the CLIP embedding space to begin with. Since it is a new word, CLIP will generate a new mapping space for it. Once the model is trained, all we need to do is use OWDva to command the model to generate pictures of D.Va, which will efficiently use all the associated tags and images of her.
Benefits of Embedding
- Compact Size: Embedding models have a small file size, so they are very easy to store and distribute. They usually only average a few hundred kilobytes.
- Efficient Training: The embedding technique makes the training process much simpler since complex tags can be mapped into one single word to more accurate objects or characters.
IN Stable Diffusion WebUI Hypernetwork:
Lastly, we should describe in some detail the Hypernetwork which is slowly getting replaced by LoRA. We will address its mechanism briefly, but it should be mentioned that Hypernetwork technology has drawbacks in relation to more modern ones.
The Basics of Hypernetwork
The principles of Hypernetwork within the context of UNET are captured in the diagram below:
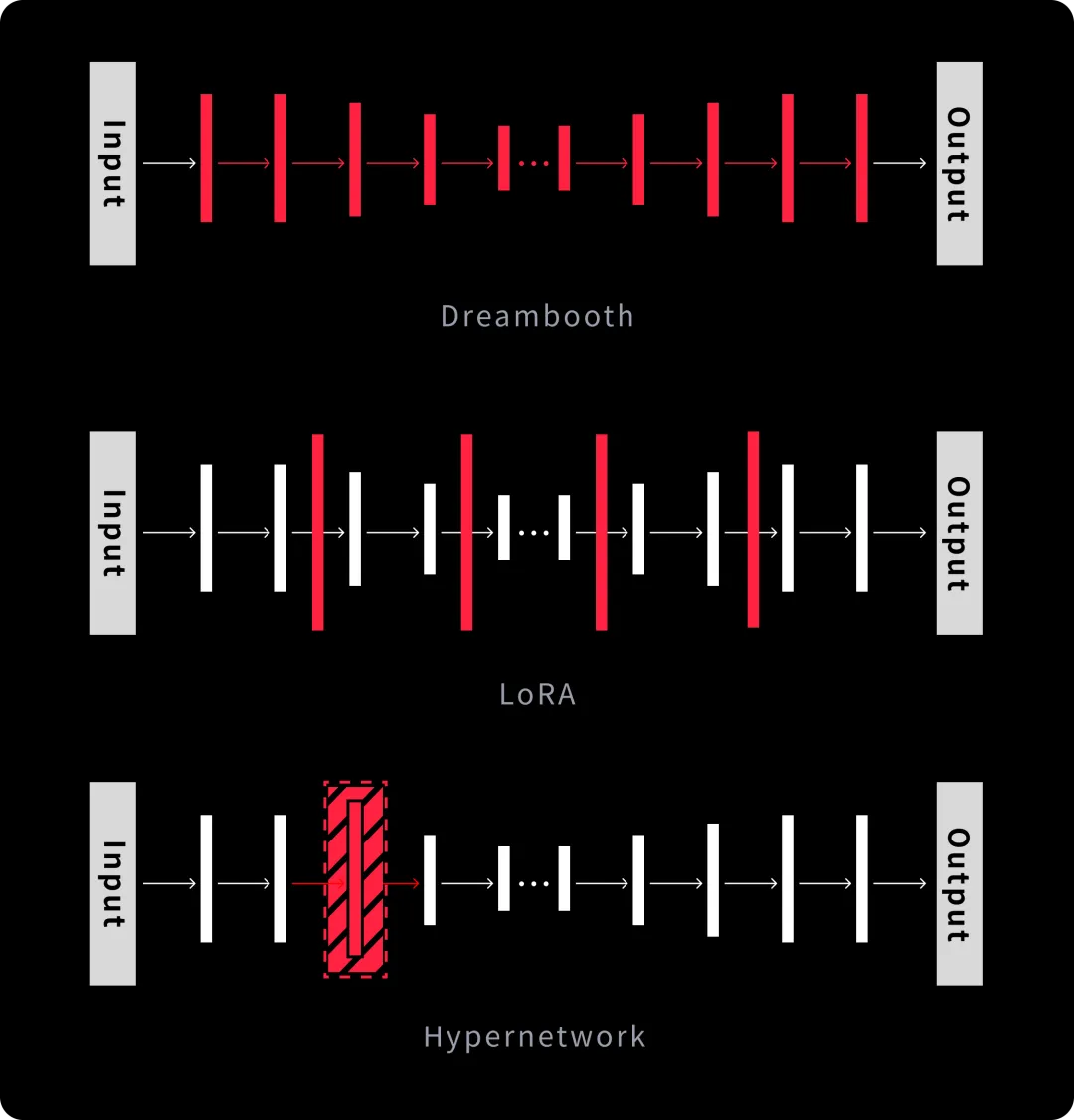
- Dreambooth: This approach modifies the entire functions and parameters of the UNET model. Therefore, it has the broadest scope of range and applications Hoever, it also has excessive training difficulty, time, and expense.
- LoRA: In contrast to Dreambooth, LoRA uses the original model’s architecture and only adds additional training parameters to some functions of Transformer, thus preserving the core model. The plug-and-play model allows for unlimited scalability, which makes it very efficient and useful. This is the primary reason why LoRA is the subject of our next lessons.
- Hypernetwork: Hypernetwork forms a new neural network model that is plugged into the middle layers of the original UNET. During the training phase, the parameters of the hypernetwork are trained while the parameters of the original model are frozen. This allows the model to constrain the instructions embedded in the input alongside the generated image by changing only a small part of the original model parameters.
LoRA: In contrast to Dreambooth, LoRA uses the original model’s
architecture and only adds additional training parameters to some functions of Transformer, thus preserving the core model. The plug-and-play model allows for unlimited scalability, which makes it very efficient and useful. This is the primary reason why LoRA is the subject of our next lessons.
Hypernetwork
Hypernetwork forms a new neural network model that is plugged into the middle layers of the original UNET. During the training phase, the parameters of the hypernetwork are trained while the parameters of the original model are frozen. This allows the model to constrain the instructions embedded in the input alongside the generated image by changing only a small part of the original model parameters.
More
If you want to explore the captivating domain of AI image generation, you are at the right plac. If you want to create breath-taking visuals with Midjourney, test the all-around power of ComfyUI, or discover the wonders of WebUI, we have all the tutorials covered that will help unleash your creativity.
Let us ask you this: How do you feel now? Are you ready to go over the limits of what your mind can think of? It is now time to accept the future, test things out, and visualize everything. Let us begin the journey into the realm of AI together.
Share this content:









Post Comment