First, I will share the latest paper about AI music with everyone.

The thesis links : https://arxiv.org/pdf/2501.09972v1
Abstract — GVMGen: AI Music Generation Model
Producing video content is crucial but quite difficult, and this has led to an increasing demand for automatic AI music generation for videos. Methods that do exist usually fail at reliable music-video matching and lack variety in their end product. This primarily stems from inadequate feature matching techniques and relatively smaller datasets.
This paper proposes a universal Video-Music Generation model GVMGen, which aims to generate the most fitting AI music for the provided input video through captioning. It utilizes a hierarchical attention approach in which video features are extracted across space and time, and are sequentially aligned to the music in a moiety where relevant content is captured and redundancy is reduced.
What demonstrates adherence to the goal of the study is also the strongest point of this approach. The music produced from different styles of video inputs is done from a gapped shot scenario. The paper also suggests how the alignment between video and AI music can be assessed using an evaluation model and two novel objective metrics introduced within this context.
Moreover, different pairs of videos and music have been placed in a consolidated multisource database. Experimental findings indicate that GVMGen achieves a better music-video correspondence than previous video models in relation to AI music and it’s range and applicability.

GVMGen: AI Music Generation Model Background
Why Music is Important in Videos
In videos, music occupies a very significant place in enhancing the emotional response of the viewer through rhythm, style, and visual representation. In most cases, video scoring has been done by a separate class of specialists which leaves nonprofessionals with problems that are very tedious and involve the risk of copyright infringements. As a result, automatic music generation for videos is important for nonprofessionals and the industry alike.
Problems Derived from Video-Music Integration
A primary problem in background music generation for videos lies in the extraction of cross-modal relations between the visual and musical components. In view of past studies, it has been attempted using rule-based connections that are computer generated like the movement speed with the color. Nevertheless, these variables only make sense for certain video types while being less applicable for video blogs and documentaries. Many other relevant variables, such as camera shots and angles, and composition especially in cinema have been ignored.
Limitations of Existing Approaches
Some studies have relied on large language models (LLMs) as intermediaries, but LLMs often reduce video and music to static styles, overlooking details such as emotions and the specific physical variables that change over time. This explicit feature alignment may ignore highly relevant information that is difficult to compute or describe, while considering irrelevant features, thus limiting the depth and coherence of music-video matching. Moreover, music features derived from variables or language transformation are often not diverse or detailed enough to guide the generation of vibrant, artistic music.
The Challenges of MIDI and Dataset Limitations
Many methods are even limited to MIDI music, which tends to be monotonous, lacking in richness, diversity, and versatility. Additionally, the lack of evaluation metrics and datasets further limits the effectiveness of video-to-music generation models. Most existing work mainly relies on subjective evaluation to measure the match between music and video, which is costly and often biased, failing to properly guide model training. Existing datasets primarily consist of music videos with MIDI-format music, which lack diversity and weakly match music with video, limiting the performance of models trained on them.
Contributions — GVMGen: AI Music Generation Model
Comprehensive Experiments
Extensive experiments were conducted, and the results demonstrate that the proposed model significantly outperforms existing models in terms of music-video matching, music diversity, and application versatility.
Proposing GVMGen
This paper introduces GVMGen, a universal video-to-music generation model based on a hierarchical attention mechanism. GVMGen is capable of generating various types of music that are highly relevant to videos of different styles.
Developing an Evaluation Model with Objective Metrics
The paper presents an evaluation model with objective metrics designed to assess the local and global alignment between music and video. Additionally, a large-scale video-music dataset has been compiled, encompassing a wide range of video and music styles.
Technical Approach — GVMGen: AI Music Generation Model
4.1 Problem Definition
In video background music generation, assume a dataset of NNN video-music sample pairs. Each video VVV is represented as:
V=(t,f,H,W,C)V = (t, f, H, W, C)V=(t,f,H,W,C)
where ttt, fff, HHH, WWW, and CCC denote the video duration, frame rate, height, width, and number of image channels, respectively.
Music is represented as quantized codes MMM:
M=(s,K)M = (s, K)M=(s,K)
where sss is the music code sampling rate, and KKK is the codebook size.
The dataset is split into a training set with NtrainN_{\text{train}}Ntrain instances and a testing set with NtestN_{\text{test}}Ntest instances. The goal of video background music generation is to accurately generate music MMM that is highly correlated with the original for the test set videos.
4.2 General Video-to-Music Generation Model
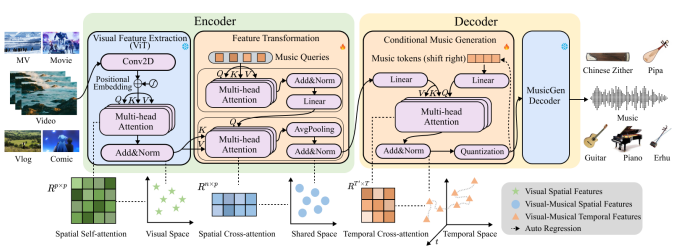
Visual Feature Extraction Module
Videos and music exist in different latent spaces, making direct transformation infeasible.
In GVMGen, pretrained ViT-L/14@336px and spatial self-attention are employed to extract deep visual features. ViT divides an image into PPP patches and transforms them into embeddings. For an image embedding xxx, the spatial self-attention calculates the importance of each patch:
z=W⋅xz = W \cdot xz=W⋅x
where WWW is a weight matrix and zzz represents the transformed features, preserving original information while deriving deeper relationships.
This method treats videos as image sequences, focusing on extracting deep intra-image features while retaining spatial and temporal characteristics for subsequent modules.
Feature Transformation Module
This module is key to video-to-music generation, establishing cross-modal relationships in a shared (visual-music) space.
GVMGen introduces spatial cross-attention to link visual and musical features. Trainable music queries qqq interact via self-attention and cross-attention with extracted visual features zzz. The attention mechanism identifies correlations between visual and music spaces, projecting visual features into the shared space, represented as cross-modal features. This ensures retention of relevant features and filters out redundant ones. Experiments show that using 16 music queries achieves optimal performance in feature filtering and transformation.
Conditional Music Generation Module
The extracted features are critical for reconstructing music.
Given that both video and music contain spatial and temporal information, GVMGen employs temporal cross-attention to guide music generation and ensure temporal alignment. This module uses a transformer decoder architecture, where query vectors are derived from shifted real music embeddings mmm. Temporal cross-attention aligns cross-modal features and music embeddings over time, enhancing global dependencies and ensuring the completeness of generated music.
The music embeddings are then decoded into audio format using the pretrained MusicGen decoder. MusicGen employs residual vector quantization (RVQ) via Encodec to compress audio streams into discrete tokens, reducing spatial complexity while generating diverse music.
To further enhance diversity and generality, a curated, vivid video-music dataset is used for training.
4.3 Evaluation Model
Traditional objective metrics like Fréchet Audio Distance (FAD) and Kullback-Leibler Divergence (KLD) primarily evaluate the similarity between generated and real music but fail to consider the correspondence between video and music.
This paper proposes an evaluation model for audio-format music with global and local (temporal) metrics. For a batch size BBB of video-music pairs, visual and music embeddings with hidden dimensions HvH_vHv and HmH_mHm are unified to a hidden size HHH.
The cross-attention matrix captures temporal video-music relationships, providing time-aligned local evaluations. Hidden features for video vvv and music mmm, fvf_vfv and fmf_mfm, are summarized via linear layers. Cross-modal correlation is computed as a global evaluation metric.
During training, mean squared error loss maximizes diagonal attention for temporal alignment, as local video-music correspondence should be strongest:
Llocal=∥A−I∥2\mathcal{L}_{\text{local}} = \|A – I\|^2Llocal=∥A−I∥2
For cross-modal correlation, InfoNCE loss is applied:
Lglobal=−logexp(sim(fv,fm)/τ)∑i=1Bexp(sim(fv,fm,i)/τ)\mathcal{L}_{\text{global}} = – \log \frac{\exp(\text{sim}(f_v, f_m)/\tau)}{\sum_{i=1}^{B} \exp(\text{sim}(f_v, f_{m,i})/\tau)}Lglobal=−log∑i=1Bexp(sim(fv,fm,i)/τ)exp(sim(fv,fm)/τ)
where III is the identity matrix, τ=0.07\tau = 0.07τ=0.07, and sim\text{sim}sim is cosine similarity.
At evaluation, time alignment and cross-modal correlation metrics are averaged. This evaluation model achieves a mean loss of 0.003 and an accuracy of 99.4% on the test set. Scores from 20 expert users on 30 video-music pairs show only a 3.75% error rate compared to the model’s evaluation.
4.4 Training Process
During visual feature extraction, each video VVV is treated as an image sequence I1,I2,…,ItI_1, I_2, …, I_tI1,I2,…,It. Each image is divided into patches pi,jp_{i,j}pi,j, where sss is the patch size. After spatial self-attention, hidden features are computed:
z={zcls,z1,…,zP}z = \{z_{\text{cls}}, z_1, …, z_P\}z={zcls,z1,…,zP}
In the feature transformation module, music-related trainable queries are introduced. These queries undergo self-attention and cross-attention with visual features, resulting in cross-modal features fvf_vfv, aggregated through average pooling.
In the conditional music generation module, cross-modal features are passed into the decoder. During training, music embeddings are derived from real music tokens and compared to predicted tokens:
L=−1K∑k=1KMklogM^k\mathcal{L} = -\frac{1}{K} \sum_{k=1}^{K} M_k \log \hat{M}_kL=−K1∑k=1KMklogM^k
During inference, music embeddings are initialized with start tokens and iteratively predicted, eventually decoded into audio-format music.
4.5 Dataset
To enhance diversity and generality, a large-scale video-music dataset was collected, covering various types of videos and music.
Existing datasets primarily consist of MIDI music in music videos (MVs), which contradicts the task of generating background music for a given video. These datasets lack diversity and feature weak video-music alignment.
The proposed dataset includes movies, video blogs, animations, and documentaries, where the background music is specifically designed for the video content. The music incorporates a significant amount of Chinese traditional music and orchestral pieces. Chinese traditional music emphasizes complex melodies, rhythms, and performance techniques that MIDI formats cannot fully capture.
The dataset was sourced from free public platforms (Bilibili and YouTube), including only clips with music while excluding videos with excessive text or subtitles. After manual screening and preprocessing, the dataset contains 147 hours of video-music pairs, distributed as follows:
- Music Videos: 89.5 hours
- Documentaries: 42.1 hours
- Video Blogs: 9.9 hours
- Other Types: 5.5 hours

Experimental Results Analysis — GVMGen: AI Music Generation Model
Performance Comparison
- Objective Metrics
Table 4 shows that GVMGen outperforms other models in terms of both similarity to real music and music-video alignment. - Models such as NExT-GPT and CoDi, which performed poorly on at least one metric and produced samples resembling audio rather than music, were excluded from further subjective evaluation.
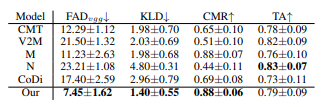
- Subjective Metrics
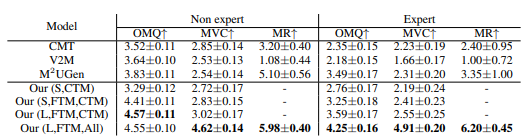
- In Table 2, based on evaluations by experts and non-experts, GVMGen demonstrates significant advantages:
- It excels in metrics such as music-video matching, music diversity, and quality.
- Even when trained only on the Chinese traditional music dataset, GVMGen outperforms other models, showcasing excellent generalizability and transferability.
Visualization Results
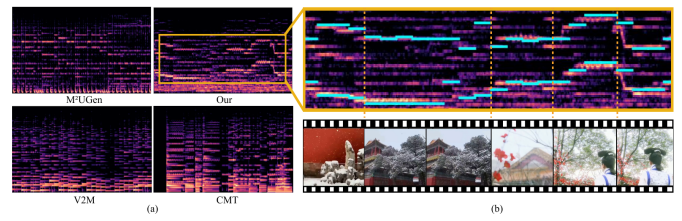
- Figure 3 illustrates how GVMGen accurately aligns the generated music with video content:
- Figure 3(a):
GVMGen is capable of generating multi-theme music, such as a composition performed by both erhu and piano, while other models fail to produce clear melodies. - Figure 3(b):
The music generated by GVMGen synchronizes with the video’s emotional dynamics over time. For instance, the music softens in background scenes and reaches a climax when the protagonist appears.
- Figure 3(a):
Generality Study

- Results in Table 3
Tested on multiple datasets unrelated to the training set, GVMGen demonstrates outstanding generalization capabilities:- It surpasses other models in similarity to real music, generated quality, and video-matching accuracy.
- Its performance in zero-shot scenarios further proves its ability to adapt to various video inputs.
Ablation Study
To further investigate the effectiveness of each component of the model, an ablation study was conducted on the spatial cross-attention and temporal cross-attention.
The objective ablation experiment used 1628 samples, each 30 seconds long, from the test set, while the subjective evaluation involved 32 samples, each 15 seconds long, from the main experiment.
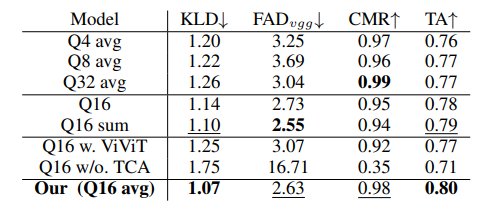
Spatial self-attention: If this module is removed, the model fails to function. As shown in Table 5, when the visual feature extraction model is changed from ViT to ViViT, both the generated similarity and music-video alignment significantly decrease, confirming the previously mentioned issue of losing temporal feature information.
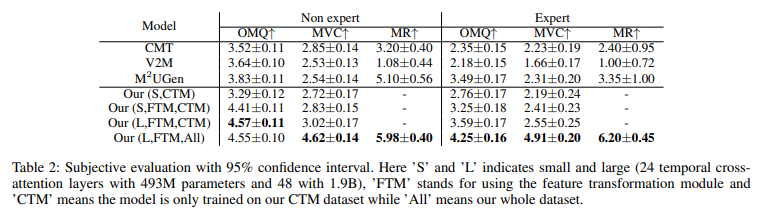
Spatial cross-attention: As shown in Table 2, removing spatial cross-attention leads to a significant drop in performance for Our (S,CTM) compared to Our (S,FTM,CTM). This demonstrates that without spatial cross-attention, visual features cannot be transformed into the shared space, resulting in lower generation quality and weaker music-video alignment.
Additionally, testing with different query counts reveals that using 16 queries yields the best performance on average. This allows the model to focus on more effective features while minimizing redundant ones.
Temporal cross-attention: As Table 5 indicates, omitting temporal cross-attention causes the generated music to deviate from the real music and become unrelated to the video. Table 2 further shows that increasing the number of temporal cross-attention layers significantly boosts nearly all metrics. This improvement stems from enhanced capacity and complexity, enabling the model to more accurately capture temporal alignment and maintain a strong correlation between the music and video.
Conclusion — GVMGen: AI Music Generation Model
This paper introduces GVMGen, a model capable of generating diverse audio-format music highly correlated with various types of video inputs.
By leveraging a hierarchical attention mechanism—including spatial self-attention, spatial cross-attention, and temporal cross-attention—the model effectively extracts and aligns latent features. This mechanism minimizes information loss while preserving the most critical features.
Additionally, the paper proposes a novel evaluation model and introduces two new objective metrics to assess the global and local alignment between music and video.
A large-scale dataset was collected, comprising music videos (MVs), films, and vlogs, covering a wide range of Western and Chinese background music styles.
Experimental results demonstrate that the proposed model excels in terms of matching accuracy, diversity, and generalization in video background music generation.
In the future, the robustness of the model and its capability for personalized music generation will be further enhanced.
Source Code :
https://github.com/chouliuzuo/GVMGen
More
If you want to dive into the breath-taking world of AI image generation,? You’ve landed in the perfect spot! Whether you’re looking to create stunning visuals with Midjourney, explore the versatile power of ComfyUI, or unlock the magic of WebUI, we’ve got you covered with comprehensive tutorials that will unlock your creative potential.
Feeling inspired yet? Ready to push the boundaries of your imagination? It’s time to embrace the future, experiment, and let your creativity soar. The world of AI awaits—let’s explore it together!
Share this content:










Post Comment