Paper :MiniMax-01: Scaling Foundation Models with Lightning Attention
Paper link :https://filecdn.minimax.chat/_Arxiv_MiniMax_01_Report.pdf
Github :https://github.com/MiniMax-AI/MiniMax-01
Use address:https://hailuoai.com/
MiniMax Open source
Open-source model context window extended to an ultra-long length, reaching 4 million tokens!
Recently, one of the “Big Six” in large models, MiniMax, released its latest open-source model series—
The MiniMax-01 series, which includes two models: basic language model MiniMax-Text-01 and visual multimodal model MiniMax-VL-01.
For the first time, MiniMax-01 significantly expands the new Lightning Attention architecture, replacing the traditional Transformer architecture, enabling the model to efficiently process a 4M token context.

In benchmark testing, the performance of MiniMax-01 is on par with top closed-source models.
MiniMax-Text-01 has shown comparable performance to recently popular models such as DeepSeek-V3 and GPT-4o, delivering impressive results in direct comparison.
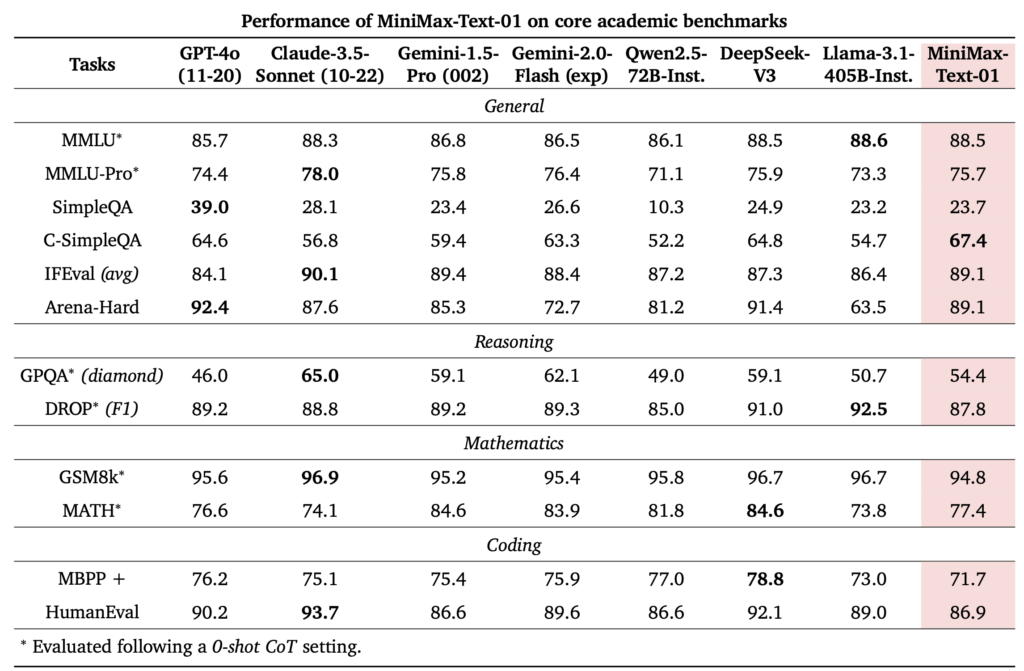
As shown in the image(c) below, when the context exceeds 200,000 tokens, the advantages of MiniMax-Text-01 become increasingly evident.
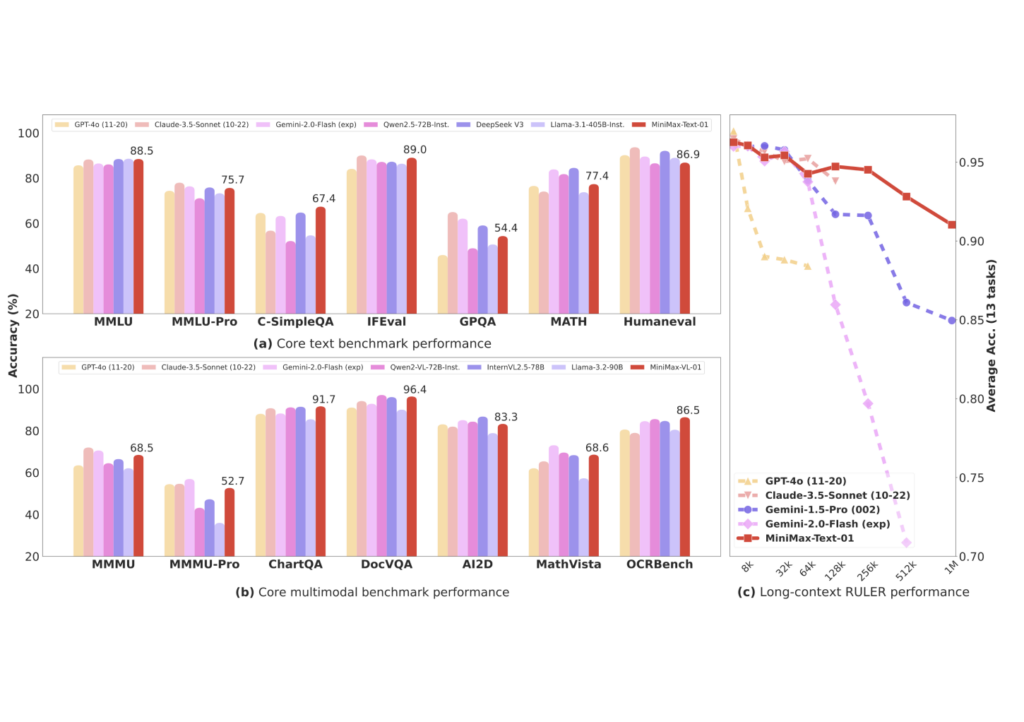
It also has a significant advantage in pre-fill latency, being more efficient and having lower latency when processing ultra-long contexts.
Netizens are calling it “incredible”!
The official statement indicates that MiniMax-01 is designed to support future applications related to agents:
Because agents increasingly need extended context processing capabilities and continuous memory.
The official team has also released a 68-page technical paper on MiniMax-01 and deployed it on Hailuo AI, offering free trials for users.
Additionally, the new model’s API pricing has been reduced:
- Input: $0.20 per million tokens
- Output: $1.10 per million tokens
More details about the model:
4M ultra-long context
MiniMax-Text-01
MiniMax-Text-01 is a model with 456 billion parameters, and it activates 45.9 billion parameters for each inference.
It innovatively uses a hybrid architecture that combines Lightning Attention, Softmax Attention, and Mixture-of-Experts (MoE).
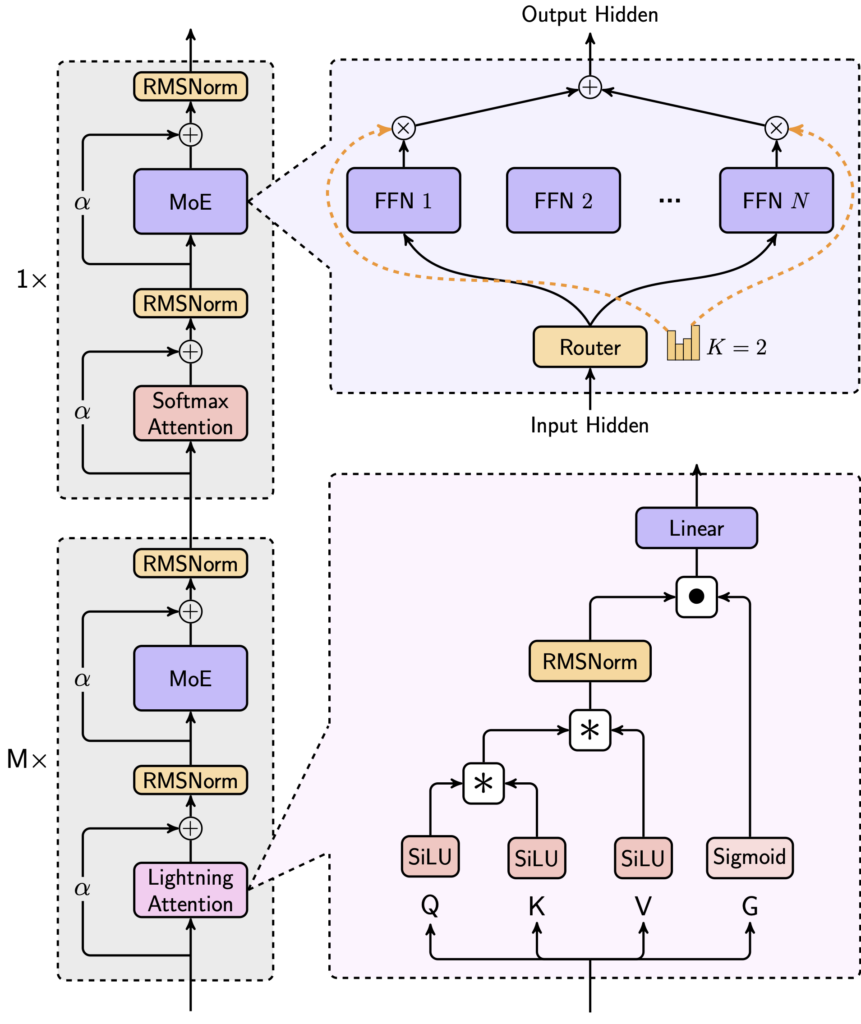
MiniMax-Text-01, through optimizations like LASP+, varlen ring attention, and ETP, employs parallel strategies and efficient computation communication overlap methods. This allows it to train with a context length of up to 1 million tokens and extend to 4 million tokens for inference.
Here are the details on the architecture:

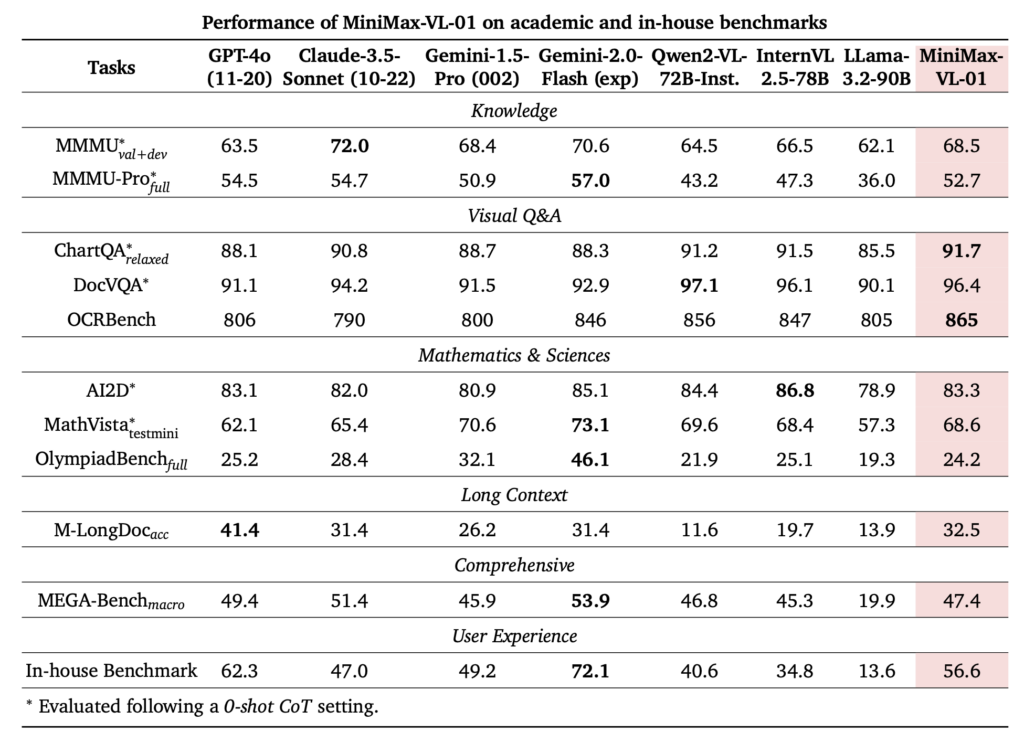
In the Core Academic Benchmark, MiniMax-Text-01 scored 54.4 points on GPQA Diamond, which is better than GPT-4o.
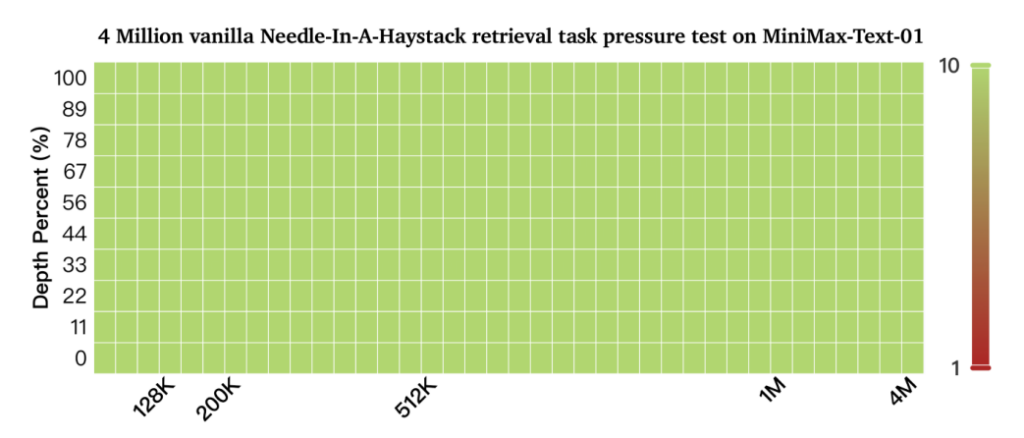
On the long benchmark test, the 4M needle-in-a-haystack test, MiniMax-Text-01 scored all green.
This means that in the 4 million score range…
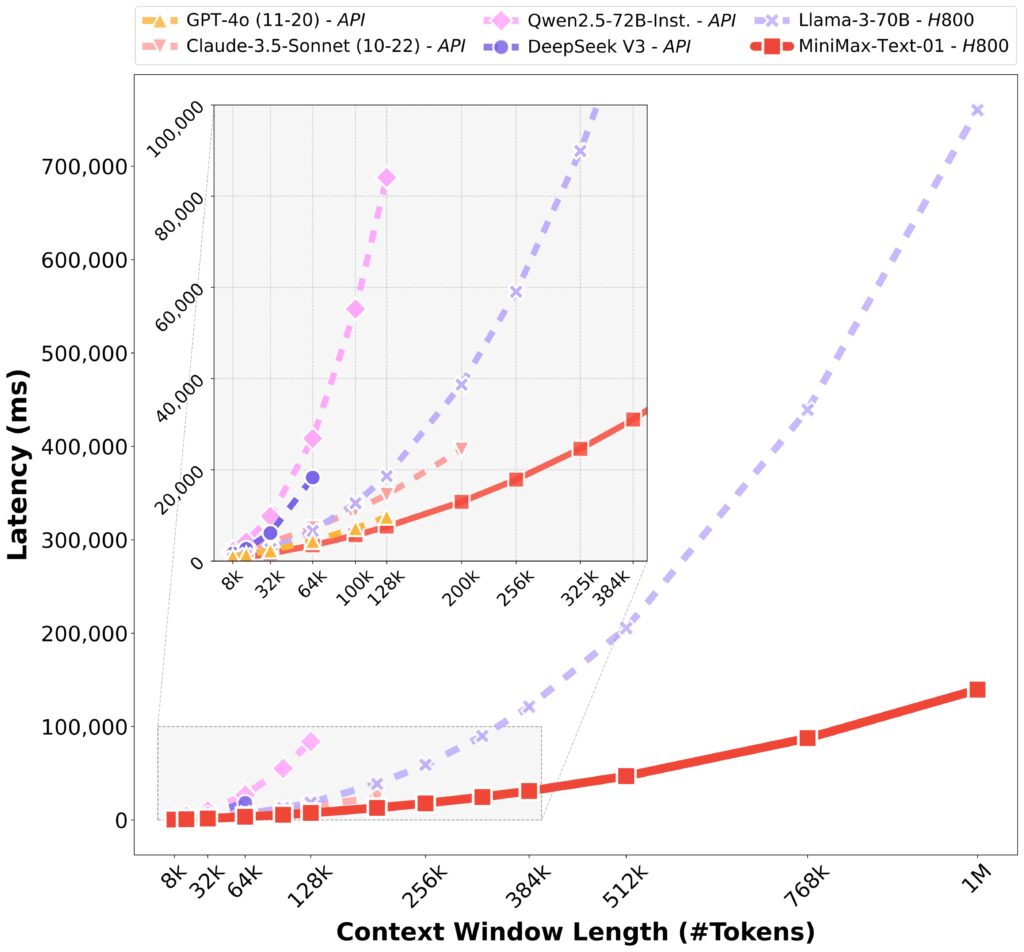
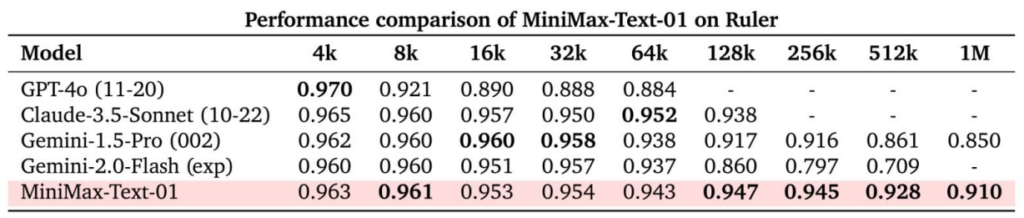
The LongBench v2 and Ruler benchmark tests evaluate a model’s ability to comprehend long-context inputs, including logical reasoning within extended contexts.
The MiniMax-Text-01 model excels in handling Ruler long-context reasoning tasks.
At the 64K input level, its performance is on par with leading models like GPT-4o and Claude-3.5-Sonnet, showing only minor differences. However, from 128K onward, MiniMax-Text-01 distinctly outperforms all benchmark models, establishing a significant advantage.
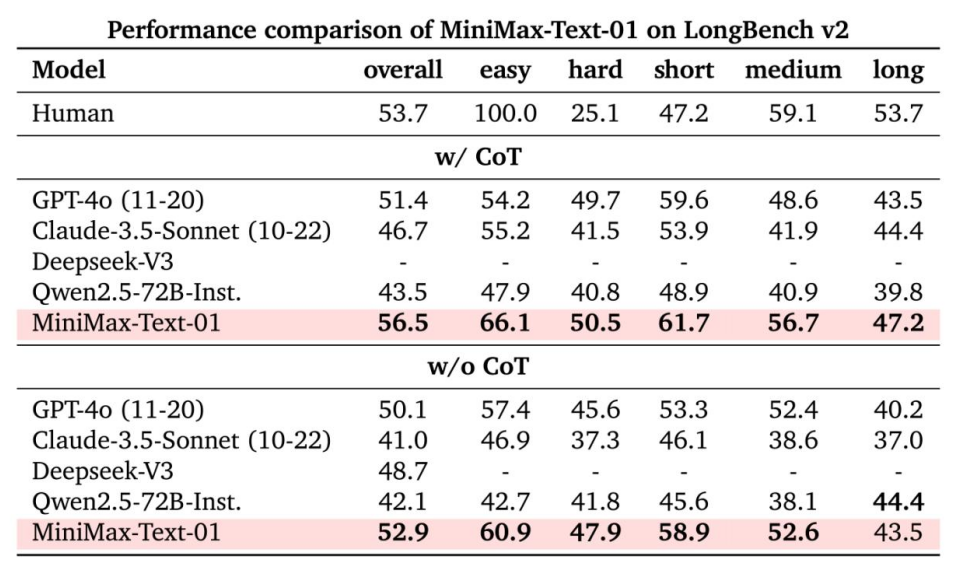
LongBench-V2 includes question-answering tasks of varying difficulty levels, covering a range of context types such as single documents, multi-document, multi-turn dialogues, code repositories, and long-structured data. The team considered two testing modes: without Chain of Thought (w/o CoT) and with Chain of Thought (w/ CoT).
MiniMax-Text-01 achieved the best results across all evaluation systems in the w/ CoT setup, and also performed significantly well in the w/o CoT setup.
The team also evaluated the model’s ability to learn from context using the MTOB (Machine Translation from One Book) dataset.
This task requires the model to translate between English and Kalamang, a language with very limited public data. In the training corpus, the LLM learned this language from only a part of a grammar book and 375 translation examples.
Test results showed that MiniMax-Text-01 had the lowest score for eng→kalam (ChrF) in a no-context scenario, suggesting that other models might have included Kalamang-related data in their pre-training or post-training datasets. However, on the delta half book and full book evaluations, MiniMax-Text-01 outperformed all other models.
In the Kalamang→eng (BLEURT) scores, MiniMax-Text-01 performed comparably to other models.
MiniMax-VL-01
Framework Overview
MiniMax-VL-01 utilizes the widely adopted “ViT-MLP-LLM” framework for multimodal large language models, comprising:
- A Vision Transformer (ViT) with 303 million parameters for visual encoding.
- A randomly initialized two-layer MLP projector for image adaptation.
- MiniMax-Text-01 as the foundational language model.
Dynamic Resolution Capabilities
MiniMax-VL-01 introduces dynamic resolution functionality, adjusting input image sizes based on a predefined grid. Resolutions range from 336×336 to 2016×2016, with a 336×336 thumbnail preserved. Adjusted images are segmented into non-overlapping blocks of identical size, which, along with the thumbnail, are separately encoded and combined into a unified image representation
Extensive Training
The model was trained on diverse data, including titles, descriptions, and instructions. ViT was developed from scratch using 694 million image-title pairs. Across four training stages, the process handled a total of 512 billion tokens.
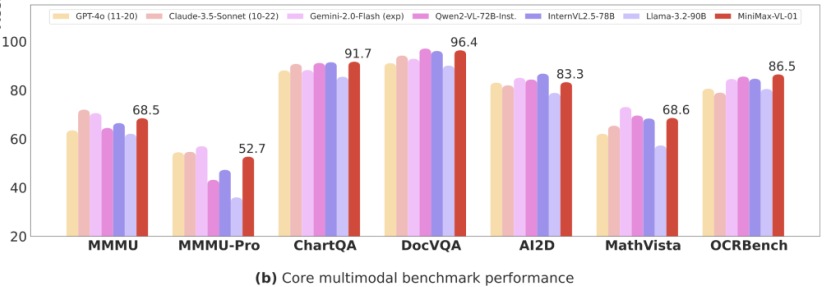
Outstanding Performance
MiniMax-VL-01 excelled in multimodal benchmarks, showcasing its capability to handle complex multimodal tasks with remarkable efficiency and reliability.odal benchmarks, demonstrating its strength and reliability in handling complex multimodal tasks.
If you want to dive into the breathtaking world of AI image generation? You’ve landed in the perfect spot! Whether you’re looking to create stunning visuals with Midjourney, explore the versatile power of ComfyUI, or unlock the magic of WebUI, we’ve got you covered with comprehensive tutorials that will unlock your creative potential.
Each guide is crafted to be both engaging and intuitive, offering you the tools to learn at your own pace. Don’t rush—enjoy the journey! Whether you’re just starting out or looking to sharpen your skills, you’ll find everything you need to master these incredible tools. And that’s not all—our tutorials are regularly updated, ensuring you’re always in the know about the latest AI trends.
Feeling inspired yet? Ready to push the boundaries of your imagination? It’s time to embrace the future, experiment, and let your creativity soar. The world of AI awaits—let’s explore it together!
Share this content:










Post Comment