Meet MEMO, the new framework that improves audio-driven avatar animation using memory-guided diffusion technology. This open-weight model, created by collaboration between Skywork AI, Nanyang Technological University, and National University of Singapore, sets the new mark on the identity-consistent emotionally-sounding video synthesis.
Key Features
✅ Multimodal Image Support
All forms of audio manipulation are perfect: portraits, sculptures (like Michelangelo’s David), digital art (for instance, Girl with a Pearl Earring), and even anime style works are animated with perfect audio sync.
✅ Versatile Audio Processing
Creepy lifelike speech animations could be done with Steve Jobs’ Stanford address, La La Land melodies, and even Kendrick Lamar rap.
✅ Global Language Coverage
English | Mandarin | Spanish | Japanese | Korean | Cantonese
✅ Emotionally Expressive
Advanced emotion transfer features can create subtle head and face movements that capture the essence of the voice being transformed.
✅ Long-Form Stability
ComfyUI Memo: Memory-Guided Diffusion Revolutionizes Expressive Talking Video Generation
Meet MEMO, the new framework that improves audio-driven avatar animation using memory-guided diffusion technology. This open-weight model, created by collaboration between Skywork AI, Nanyang Technological University, and National University of Singapore, sets the new mark on the identity-consistent emotionally-sounding video synthesis.
Key Features
✅ Multimodal Image Support
All forms of audio manipulation are perfect: portraits, sculptures (like Michelangelo’s David), digital art (for instance, Girl with a Pearl Earring), and even anime style works are animated with perfect audio sync.
✅ Versatile Audio Processing
Creepy lifelike speech animations could be done with Steve Jobs’ Stanford address, La La Land melodies, and even Kendrick Lamar rap.
✅ Global Language Coverage
English | Mandarin | Spanish | Japanese | Korean | Cantonese
✅ Emotionally Expressive
Advanced emotion transfer features can create subtle head and face movements that capture the essence of the voice being transformed.
✅ Long-Form Stability
Extended dialogues could now be done without accumulating too much error; you can constantly hold high quality conversations that exceed 2-3 minutes.
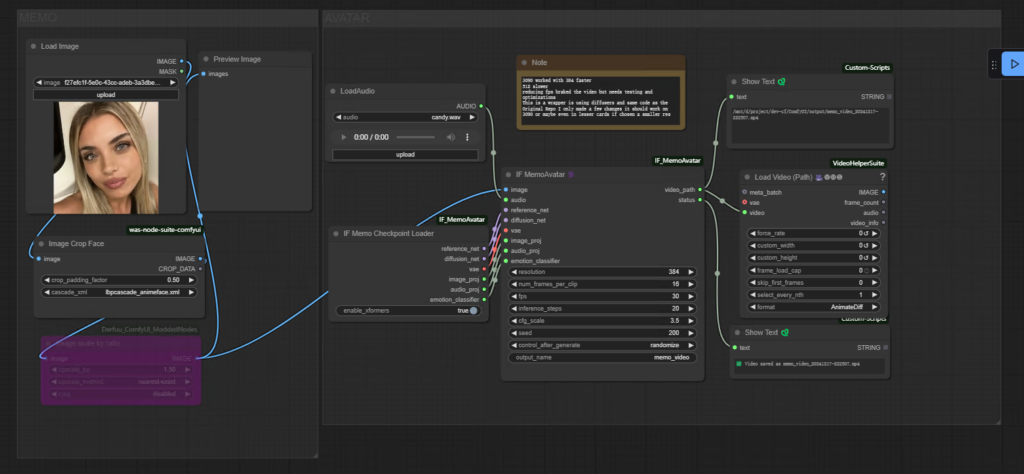
Technological Innovations
The functionalities of MEMO are brought to the ComfyUI workflow with the official ComfyUI-IF_MemoAvatar plugin:
1️⃣ Memory-Guided Temporal Module – Preserves identity consistency
2️⃣ Emotion-Aware Audio Module – Improves lip sync captivated.
Integration ComfyUI
Check the ComfyUI Manager to install.
Search for: “IF_MemoAvatar”

Plugin Features
🎨 Video generation with a certain style.
📹 HD resolution output (512×512)
👄 Lip sync powered by audio with a high level of precision.
🎭 Transfer animation while preserving emotion.
Installation Guide
Install plugin through ComfyUI Manager
Required models auto-download to:
Checkpoints: /ComfyUI/models/checkpoints/memo/
Audio Models: /ComfyUI/models/wav2vec/
VAE: /ComfyUI/models/vae/sd-vae-ft-mse/
Manual Download Links: MEMO Models
System Requirements
Linux: pip install xformers
Windows: Triton/Sage Attention Guide
Critical Configuration
Ensure models.json exists in root directory with proper entries.
Verify /misc/face_analysis/version.txt contains “0.7.3”.
Put in
Put out
More
If you want to dive into the breath-taking world of AI image generation,? You’ve landed in the perfect spot! Whether you’re looking to create stunning visuals with Midjourney, explore the versatile power of ComfyUI, or unlock the magic of WebUI, we’ve got you covered with comprehensive tutorials that will unlock your creative potential.
Feeling inspired yet? Ready to push the boundaries of your imagination? It’s time to embrace the future, experiment, and let your creativity soar. The world of AI awaits—let’s explore it together!
Share this content:










Post Comment