- Stable Diffusion WebUI Basic 01–Introduction
- Stable Diffusion WebUI Basic 02–Model Training Related Principles
- Stable Diffusion WebUI Basic 03– FineTuning Large Models
Foreword of Stable Diffusion WebUI Basic
In the context of Basic Stable Diffusion WebUI, it is important to remember that there are plenty of methods one can try out regarding AI image generation. If you want to know more about Midjourney, click there for the tutorial. For ComfyUI, click there for the tutorial. The objective of this series is to explain how to use Stable Diffusion WebUI in a more systematic manner. From simple tasks to highly detailed ones, we will assist you in mastering the powerful features of the WebUI so that you can achieve fantastic results when generating AI images.
By the end of this article, you will be able to grasp the core concepts surrounding Stable Diffussion in a simplified way. Your understanding will include the following:
- How does a computer interprets images?
- How does one train models?
Stable Diffusion WebUI Basic algorithm principle — Machines Recognize Images
During the training phase, the computer uses a machine learning method known as supervised learning that matches description to image. In this stage of the process, image recognition, natural language processing, and convolutional neural networks (CNNs) are used to identify certain patterns within those images. This model is trained utilizing extremely large labeled datasets so that links between visual features and concepts are accurately made so an object can be identified in new visuals.

While training a machine learning model to identify images, we add a dataset such as dogs and label the images as “dog”. The machine processes the images to learn and attach certain features associated with the label assigned. Through billions of iterations, the model captures the patterns and features and learns what a dog is by “recognizing” the features associated with a dog.
Stable Diffusion WebUI Basic algorithm principle — Models trained
Now, let us pretend like the machine has the ability to recognize everything. After years of training, the model begins to learn the features of a “cute girl” and make errors like drawing three eyes or two mouths. The model draws image A after being inputed “cute girl”. Image A does not match the description, so the programmers are forced to modify the model so it resembles image B more closely. These modifications are saved in a .ckpt file, along with the model that was trained.
The whole process is shown below:
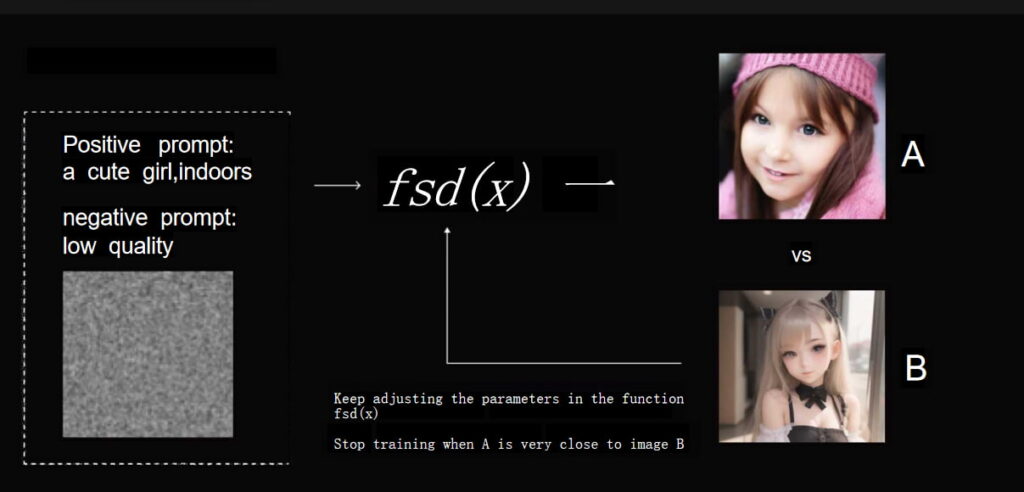

A few things to consider when downloading models from C-Station are the following two files:
- safetensors: These files are saved using NumPy and contain only the tensors. There is no extra code saved with the file, making it safer and faster to load.
- ckpt: These files use Pickle serialization format which can, in some ways, be dangerous because it can store overreaching code. Be careful when downloading from sources you don’t trust.
Because of the points mentioned above, always try to download .safetensor files first because they are much safer.
More Tutorial
If you’re excited to dive into the world of AI image generation, you’ve come to the right place! Want to create stunning images with Midjourney? Just click on our Midjourney tutorial and start learning! Interested in exploring ComfyUI? We’ve got a detailed guide for that too. Each guide is designed to be simple and fun, helping you master these powerful tools at your own pace. Here, you can learn all the AI knowledge you need, stay updated with the latest AI trends, and let your creativity run wild. Ready to start? Let’s explore the exciting world of AI together!
Share this content:









1 comment